Now don’t worry, I’m not about to start blogging every week, I’ve just got some free time at the moment.
Earlier in the summer I was asked how difficult would it be to take a unknown stream of data and make some Log Insight events from that data and how long would it take. That’s pretty hard to quantity given the ‘unknown stream’, but sending data into Log Insight isn’t particularly difficult via the REST API, if you know what you’re doing. The conversation went quiet until much later when I was asked again. This typically means someones doing something interesting but again there was no information about the incoming data stream (and it’s probably an odd use-case to send non logs to a syslog server), but it intrigued me. This is also a great opportunity to revisit my blog on webshims because any solution will involve a box sitting in the middle taking the incoming stream and formatting it into a REST API call to vRealize Log Insight.
Drafting a solution
Because I’ve no idea of the incoming data stream I started in the middle: standing up a webshim and then making a module that sends information into vRealize Log Insight.
Grabbing my old notes, I opened up a Linux server and grabbed the webhooks code from the VMware GitHub repository using the ‘manual’ steps with an additional step. To be clear, this is to quickly build a Flask webserver that I can use as a starting point. The steps used are:
- virtualenv loginsightwebhookdemo
- cd loginsightwebhookdemo
- source bin/activate
- git clone https://github.com/vmw-loginsight/webhook-shims.git
- cd webhook-shims/
- pip install -r requirements.txt
- pip install markdown
At this point I can run the standard VMware webserver
python3 run-server.py 5001Writing the vRealize Log Insight Event Shim
Before I get into this, lets all remember that I’m not a programmer and I don’t know Python particularly well either. I’m sure there’s better ways to do this, or I’m breaking some rule somewhere.
The first job is to create a source file for the vRealize Log Insight shim, starting with various functions and libraries that will be need:
from loginsightwebhookdemo import app, callapi
from flash import json
import time
from datetime import datetimeFrom the original __init__.py file I want to use app and callapi, otherwise the rest of the file isn’t required for this. Log Insight is expecting JSON formatted events with the appropriate time, specified in epoch time.
Next I tend to have the Variables and Constants. This is where I place all the hard coded bits and bobs or adjustable code so I can manipulate the script without re-writing stuff.
# Variables
VRLI_URL = "https://<FQDN_VRLI>"
VRLI_API_EVENTS_UUID = "111-MY-TEST-VM"
# Constants
VRLI_API_URL = ":9543/api/v1"
VRLI_API_EVENTS_URL = "/events/ingest/"
VRLI_HEADER = {"Content-Type": "application/json"}This is fairly explanatory apart from the ‘UUID’. When sending an event via the REST API to Log Insight the URL must end in a UUID. This UUID must be unique, but it appears to be free text. I make the UUID up and the messages arrive. In any environment this will probably need to change, so I have a variable and give it a random string. This is not the ‘source’ magic field, in fact, I’ve not seen where this UUID is surfaced in the Log Insight UI.
Now it’s time to define the main core of the webshim. This will be the entry point and it will accept a block of text and format it for ingestion by Log Insight.
@app.route("/vrli_event/<EVENT_INPUT>", methods=['POST'])
def vrli_event(EVENT_INPUT=None):
eventDetails = {}
buildCustomDict(eventDetails, EVENT_INPUT)
VRLI_FULL_URL = buildVRLIURL()
MESSAGEDATA = {
"events":[{
"text": eventDetails['eventMessage'],
"timestamp": eventDetails['eventTime']
}]
}
return callapi(VRLI_FULL_URL, 'post', json.dumps(MESSAGEDATA), VRLI_HEADER, None, False)The function is called with a passed block of text, which I reference with <EVENT_INPUT>. I then create a python list ( eventDetails = {} ) which I will use to store the data that I want to send to Log Insight. The next line ( buildCustomDict() ) is passed the newly created list object and the message block. The list is then updated with the text block, and the epoch time. We will look at this function shortly.
NOTE: I chose to do it this way to make it easier to adjust the code in the future. On longer code, I often track a number of internal variables with a list which enables me to keep things organised before I output to a log file.
I then build the full REST API URL ( VRLI_FULL_URL = buildVRLIURL() ) before building the correct JSON structure for the message block. Then I use the callapi function to post the event to Log Insight.
Fairly straight forward.
I then need to flesh out two additional functions:
- buildCustomDict()
- buildVRLIURL()
buildCustomDict(responseDict, dictInput=”ERROR – No Event Passed”)
Builds the structure of the passed list, known as responseDict and records the passed message block, with an error message if nothing is passed.
humantime = datetime.today()
epoch, spare = (str(time.mktime(humantime.timetuple()))).split(".")
responseDict.update({
"eventMessage": dictInput,
"eventTime": epoch,
})
returnThe line ( epoch, spare = (str(time.mktime(humantime.timetuple()))).split(“.”) ) takes the current date (held in the humantime variable) and converts it to an epoch time, which seems to be in the format XXXXXXX.0. This doesn’t actually work with Log Insight, so I convert it to a string and then split the string. The variable spare is the trailing 0 and is ignored.
NOTE: It appears that just sending a message into Log Insight via API without a epoch time specified will allow Log Insight to just assign the current time when the event was processed.
buildVRLIURL()
This is a simple function that builds the complete URL that I will post to. This could be done within the main function but I typically split these out in case I refactor the code later on. In this instance I might want to rejig this based on UUIDs, so to avoid re-coding the main function I can just fiddle with this function.
output_URL = VRLI_URL + VRLI_API_URL + VRLI_API_EVENTS_URL + VRLI_API_EVENTS_UUID
return output_URLAnd that’s the bulk of the code, minus lots of logging code. Nothing too difficult.
Testing the code
I also wrote an additional very small function that takes a block of text and converts each sentence into a log message.
TEXT_EXTRACT="Blah. Blah. Blah."
@app.route("/read_format_text")
def read_format_text():
LINES = TEXT_EXTRACT.split(".")
LINES_COUNT = len(LINES)
for LINES_COUNT in LINES:
vrli_event(LINES_COUNT)
returnFor space here I’ve swapped out the text for ‘Blah. Blah. Blah.‘
To call the test function:

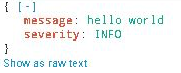
oooh, look at that. It works, albeit I’ve not bothered to code a trim in to prune the errant spaces.
Ok, well that’s an horrific insight into my code but how would I expect this to actually be deployed? Well, actually, in keeping with modern’ish IT, a container. So lets stick all this into a container and run it via Docker.
Building a Docker container
I could just hatchet the VMware Docker image, but it’s 3 years old and running Photon 1. I want to use the latest Photon (Photon 4), so lets build an fresh docker image.
In my collection of VMs I already had a Photon 4 OS lying around (you mean you don’t??) so I grabbed it and turned Docker on and set it to start automatically (it’s off by default):
systemctl start docker
systemctl enable docker
docker info
To create a docker image you need to build up the various layers, starting with the basic image. In my docker file I added the following lines:
FROM photon
RUN yum -y update
RUN tdnf install python3 python3-pip -y
RUN python3 -m pip install Flask requests markdown
RUN mkdir vrli_webshim
COPY vrli_webshim /vrli_webshim
COPY vrli_webshim/webshims /vrli_webshim/webshimsI’m basically grabbing the latest Photon image and updating it. Then I install Python and PIP, using the newly installed PIP to install some Python modules and then make the folder structure I need. The two copy commands copy my code into the docker image file. I had to specifically copy the child folder structure.
Once that file was completed and I had my code placed into the same folder it was time to build the Docker image:
docker build -t vrli-webshim:0.1 .Then I ran the image:
docker run --network host -it vrli-webshim:0.1I used –-network host because this is on a nested VM and this was the quickest way to get access to the web front end. Because I ran this as an interactive session ( -it ) I can manually run the webshim:
python3 /vrli_webshim/runserver.py 5001
It’s alive!!
And if I trigger the test function:
Good golly gosh. and bonus Games Workshop lore as well. You lucky people. Time for a coffee.
…one minute week later…
That was a long coffee. Where was I? Oh yes. Lets get the docker container starting automatically upon the server boot.
To do this we need to amend the DockerFile to run the following command. This is added to the very end of the DockerFile.
CMD ["python3", "/vrli_webshim/runserver.py", "5001"]The CMD call takes an array of parameters consisting of the primary call, followed by a number of arguments. Rebuilding the image (as a new interation) and testing shows that the container now automatically starts the Flask server.
docker build -t vrli-webshim:0.2 .
docker run --network host -it vrli-webshim:0.2

Time to configure the Photon machine to start this new container on reboot and then we have a self-contained image. This appears to be a fairly straightforward additional argument on the docker start upline:
docker run --restart always --network host -it vrli-webshim:0.2A few test reboots and it appears that the webshim is starting automatically.


Time to export this new image:
docker save vrli-webshim:0.2 > vrli-webshim.tarAnd via the magic of SFTP I’ve copied it to a new Linux machine, based on Mint.

Lets import that image see if this works.
docker load < vrli-webshim.tar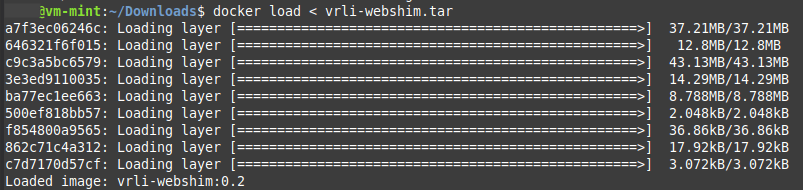
And does it run?
docker run --network host -it vrli-webshim:0.2
Yes it does. To make it run upon startup I would need to add the –restart argument as obviously this is a docker instance specific argument.
And does the test function work…
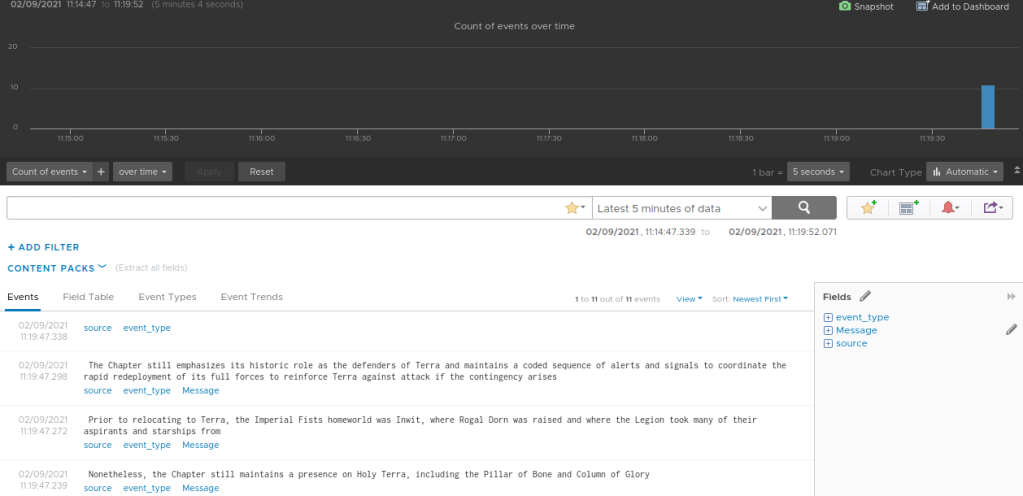
Excellent. To recap, I’ve built a portable containerised webshim, using a new Photon4 base image that will take an array of strings and send that array as messages to Log Insight. The other side would be an additional webshim that captures the random text and does some formatting based upon the exact nature of the incoming data stream.
Might be time for a biscuit.