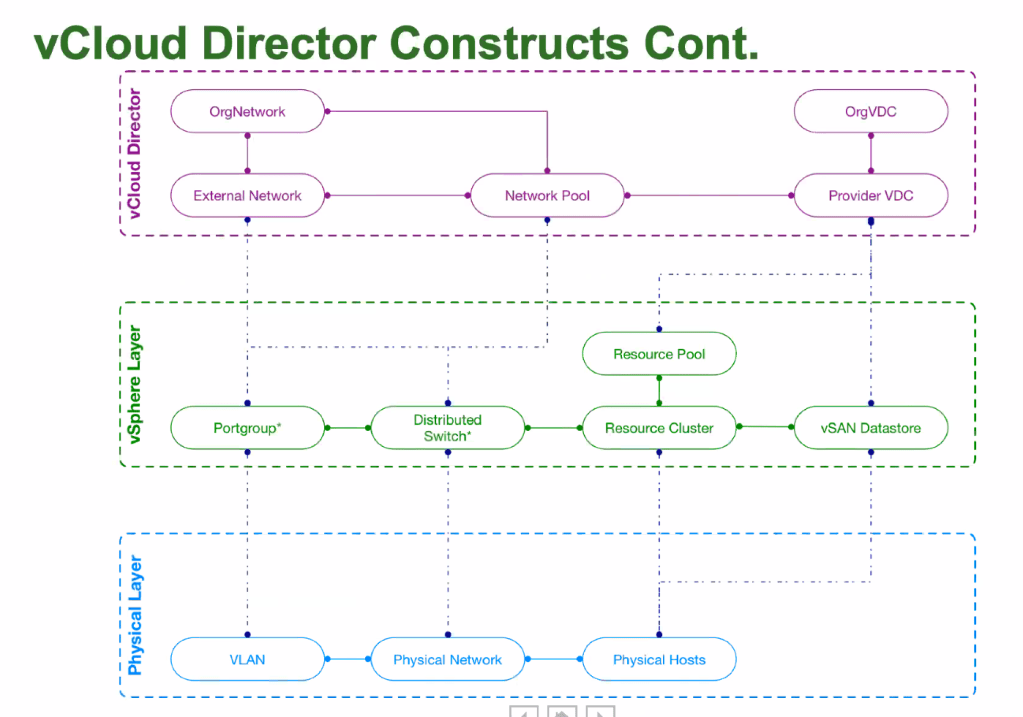
History Recap: In vRealize Operations 6.7 the capacity engine was re-engineered and the Allocation modelling capability was removed before being re-added in vRealize Operations 7.5. There’s no Allocation in vRops 6.7 to 7.0. You also need to enable Allocation in the policies in vROps 7.5, it’s not turned on out of the box (OOTB).
There are two primary classifications of reviewing capacity within vRealize Operations:
Demand – Capacity based upon the actual requested resource consumption (i.e. demand). Demand-based modelling is typically used by Managed Service Providers (MSP) as it represents the actual usage of the environment which has been licensed to other users. The more accurate the model. the more resources can be sold and the more money is made (let’s be honest it’s about the money!).
Allocation – The total consumption of a resource if it theoretically was used at 100% all the time. This is an older model that can be much simpler as it’s essentially just a subtraction from the total capacity. I typically find allocation in larger organisations where the IT infrastructure supports various different business organisations and cross-charging (or chargeback) is performed to help offset the IT costs. It’s also much easier to plan with as simply when it gets up to roughly ~75% allocated, you buy more hardware.
I’m going to talk about the Allocation model. As I see it, the allocation model has two primary use-cases, each with its own distinct event horizon (this is my terminology):
Short event horizon: I’m deploying new objects (VMs / Containers / whatever) right now or in the next few days. I need to know what the available capacity is right now. Therefore my usable capacity must exclude all resource providers (hosts, storage etc) that are not contributing (aka offline, in maintenance mode etc) to the capacity.
Long event horizon: I’m deploying new objects in a year. This is important when it takes a long time to purchase and prepare new hardware. Therefore my usable capacity should take the assumption that all of the resource providers are online and available. There’s probably no reason (I have one or two TBH, but that’s not the point here) for a resource provider to be offline / in maintenance mode for an extended period of time.
The Allocation model in vROps 6.6.1 was based upon the long event horizon. Hosts that where in maintenance mode were included in the usable capacity metrics.
The Allocation model in in vROps 7.5+ is based upon the short event horizon. Hosts that are in maintenance mode are not included in usable capacity.

Is this a problem?
It depends on the exact methodology used when trying to do long term planning. In large environments it’s a constant job to lifecycle manage the underlying infrastructure. There are almost always hosts in maintenance mode for patching and the inevitable hosts that are just going pop (at night, it’s always at night!).
It’s also worth remembering that the capacity planners (long-term) are not the same people that are often doing the deployments (short-term). There’s a whole raft of reasons the capacity planners might not even have access to vROps (operational, cultural, procedural), so the long term capacity planning might actually be done via data extract and not the UI. So that lovely ‘What-if’ functionality isn’t used (DevOps and SREs are typically code driven).
What does this affect?
This behaviour is seen in the following two metrics:
- CPU|Allocation|Usable Capacity after HA and Buffer
- Memory|Allocation|Usable Capacity after HA and Buffer
As far as I’m aware Disk Space|Allocation”Usable Capacity after HA and Buffer doesn’t have this behaviour (as you’d expected TBH).
I have this problem, what can I do about it?
In the most basic long term allocation modelling it’s fairly straight-forward to model using supermetrics.
For example, let’s talk about CPU.
The allocation model, at the cluster level, models CPU capacity as vCPU. That is the total number of vCPU that can be deployed.
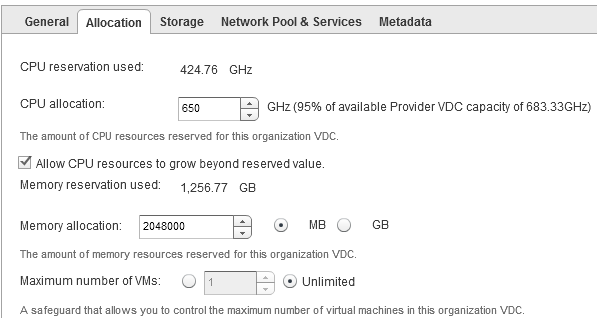
The standard OOTB metric for this is ‘CPU|Allocation|Usable Capacity after HA and Buffer‘ and it will show a usable capacity and this metric will vary depending on if hosts are in maintenance mode <See image above>.
Lets build a basic replacement that doesn’t care if hosts are in maintenance mode.
This calculation can be something fairly simple as:
((CPU|Number of physical CPUs (Cores) * ratio) * Cluster Configuration|DAS Configuration|Admission Control Policy|CPU Failover Resource Percent)) – (((CPU|Number of physical CPUs (Cores) * ratio) * Cluster Configuration|DAS Configuration|Admission Control Policy|CPU Failover Resource Percent)* buffer)) = Cluster Usable Capacity vCPU
Let’s use some numbers to see how this works. I’ve assumed the following (OOTB represents the vROps OOTB metric name if you need it):
- Number of hosts in a cluster = 12
- (OOTB: Summary|Total Number of Hosts)
- Number of cores per host = 20
- Number of physical CPUs in a cluster (or cores * hosts) = 240
- (OOTB: CPU|Number of physical CPUs (Cores)) – this is variable though as it excludes hosts in MM.
- Desired Ratio = 4:1
- HA FTT = 1 Host
- (OOTB: Cluster Configuration|DAS Configuration|Admission Control Policy|CPU Failover Resource Percent)
- vROps additional Buffer = 5%
To the math:
(Total Hosts * Cores per host) = 240 physical cores (or OOTB: CPU|Number of physical CPUs (Cores))
240 * Ratio (4:1) = 960 vCPUs Total Capacity
(This could be a cool SM if you wanted to know the total number of vCPUs for a cluster, which vROps currently doesn’t tell you).
960 vCPU TC – OOTB: Cluster Configuration|DAS Configuration|Admission Control Policy|CPU Failover Resource Percent (8%) = 960 * 0.92 = 883.2 vCPU
883.2 * vROps buffer (5%) = 883.2 * 0.95 = 839.04 vCPU
Wrap the whole metric in the floor() function to get 839 vCPU as your usable HA content that will not change if hosts are in maintenance mode.
You can do something similar for Memory|Allocation|Usable Capacity after HA and Buffer as well, and that should be simpler.
NOTE: I’ve simplified the calculations above from the eventual supermetric customer delivered supermetric, and due to the hosting platform I currently can’t get formula’s to look nice so a few brackets might be misplaced.
How complicated can the supermetrics get?
Very very complicated depending on your particular requirements. Go beyond the very basics and it can include vROps SM if statements, which statements, arrays. Quite advanced supermetric stuff and if you really want to go to town, calculations scripted outside of vROps and then inserted into vROps.
If you’re really struggling I would recommend engaging with VMware about getting Professional Services involved.